The Execute Pipeline¶
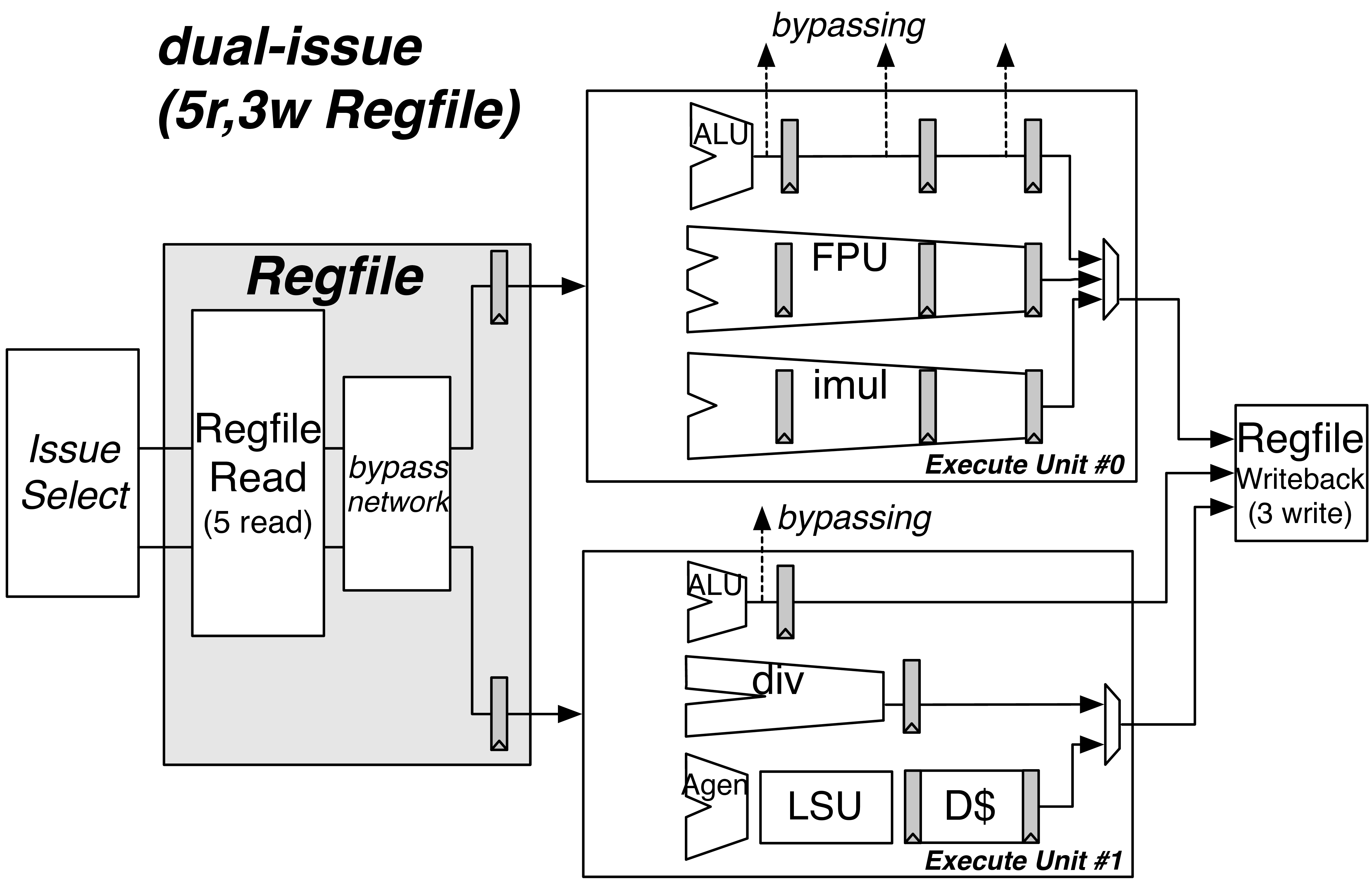
Fig. 19 An example pipeline for a dual-issue BOOM. The first issue port schedules UOP<Micro-Op (UOP)`s onto Execute Unit #0, which can accept ALU operations, FPU operations, and integer multiply instructions. The second issue port schedules ALU operations, integer divide instructions (unpipelined), and load/store operations. The ALU operations can bypass to dependent instructions. Note that the ALU in Execution Unit #0 is padded with pipeline registers to match latencies with the FPU and iMul units to make scheduling for the write-port trivial. Each :term:`Execution Unit has a single issue-port dedicated to it but contains within it a number of lower-level :term:`Functional Unit`s.
The Execution Pipeline covers the execution and write-back of Micro-Ops (UOPs). Although the UOPs<Micro-Op (UOP) will travel down the pipeline one after the other (in the order they have been issued), the UOPs<Micro-Op (UOP) themselves are likely to have been issued to the Execution Pipeline out-of-order. Fig. 19 shows an example Execution Pipeline for a dual-issue BOOM.
Execution Units¶
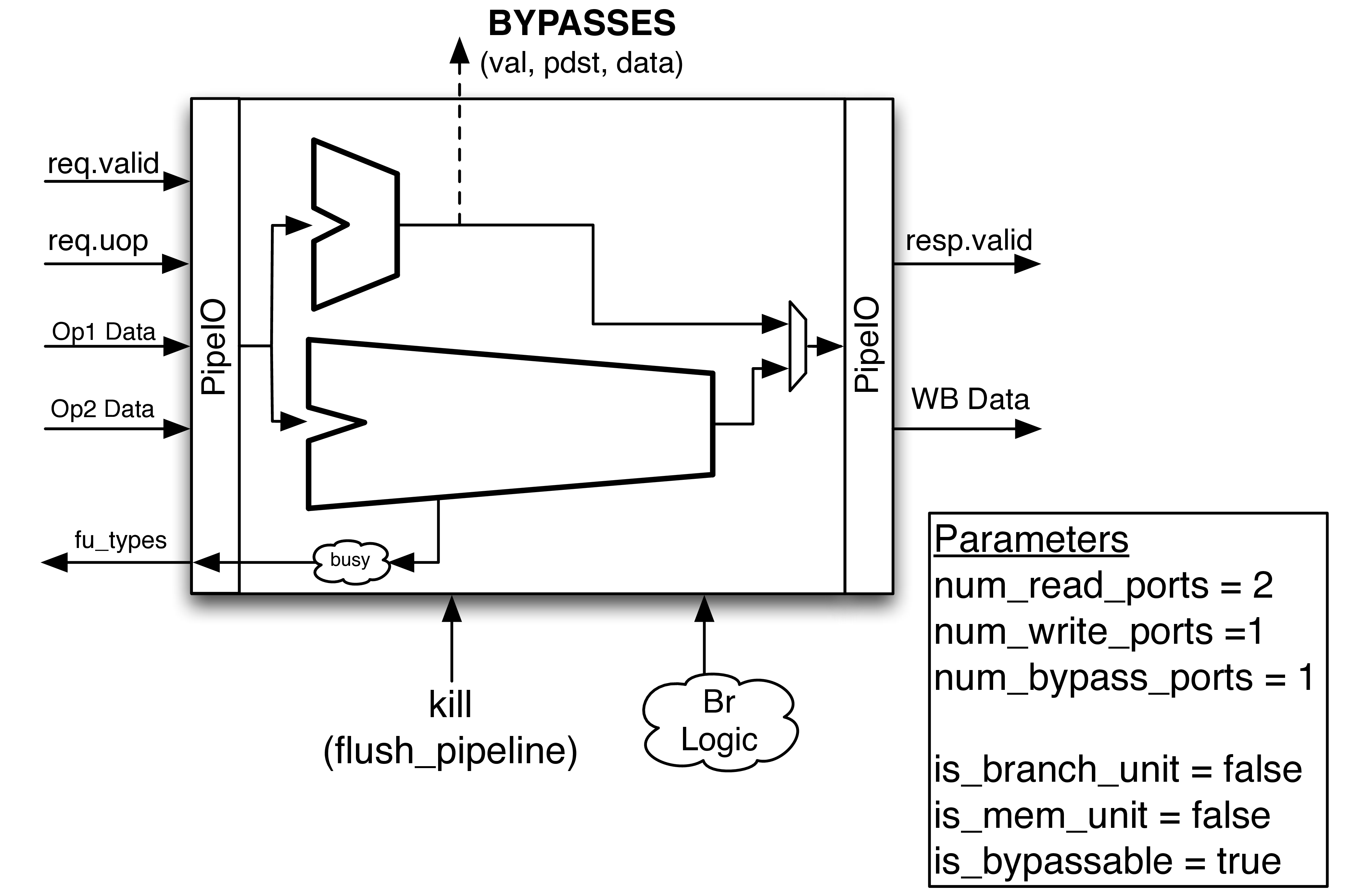
Fig. 20 An example Execution Unit. This particular example shows an integer ALU (that can bypass results to dependent instructions) and an unpipelined divider that becomes busy during operation. Both Functional Unit`s share a single write-port. The :term:`Execution Unit accepts both kill signals and branch resolution signals and passes them to the internal Functional Unit s as required.
An Execution Unit is a module that a single issue port will schedule UOPs<Micro-Op (UOP) onto and contains some mix of Functional Unit s. Phrased in another way, each issue port from the Issue Queue talks to one and only one Execution Unit. An Execution Unit may contain just a single simple integer ALU, or it could contain a full complement of floating point units, a integer ALU, and an integer multiply unit.
The purpose of the Execution Unit is to provide a flexible abstraction which gives a lot of control over what kind of Execution Unit s the architect can add to their pipeline
Scheduling Readiness¶
An Execution Unit provides a bit-vector of the Functional Unit s it has available to the issue scheduler. The issue scheduler will only schedule UOPs<Micro-Op (UOP) that the Execution Unit supports. For Functional Unit s that may not always be ready (e.g., an un-pipelined divider), the appropriate bit in the bit-vector will be disabled (See Fig. 19).
Functional Unit¶
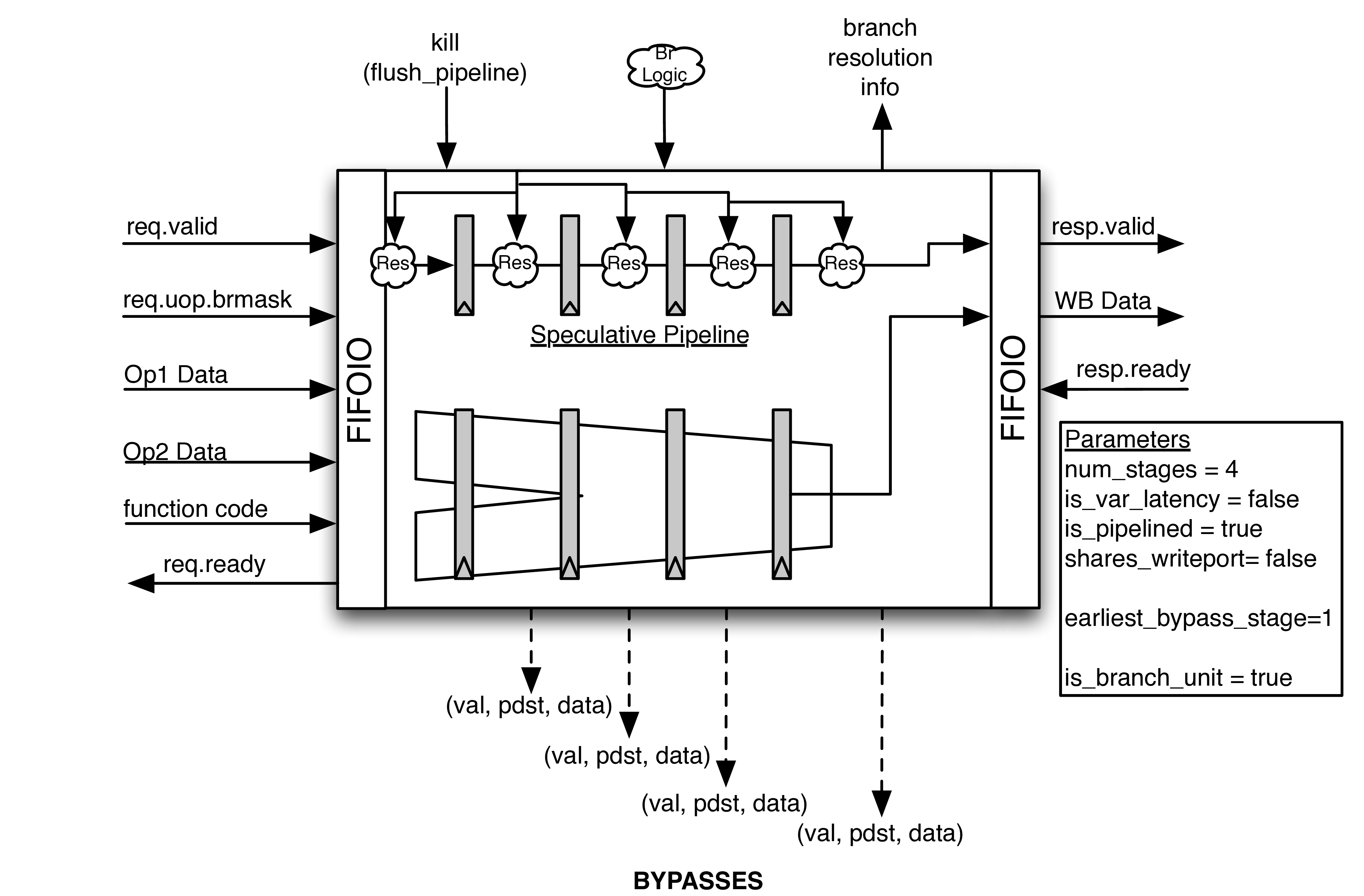
Fig. 21 The abstract Pipelined Functional Unit class. An expert-written, low-level Functional Unit is instantiated within the Functional Unit. The request and response ports are abstracted and bypass and branch speculation support is provided. UOPs<Micro-Op (UOP) are individually killed by gating off their response as they exit the low-level Functional Unit .
Functional Unit s are the muscle of the CPU, computing the necessary operations as required by the instructions. Functional Unit s typically require a knowledgable domain expert to implement them correctly and efficiently.
For this reason, BOOM uses an abstract Functional Unit class to “wrap” expert-written, low-level Functional Unit s from the Rocket repository (see Rocket Chip SoC Generator). However, the expert-written Functional Unit s created for the Rocket in-order processor make assumptions about in-order issue and commit points (namely, that once an instruction has been dispatched to them it will never need to be killed). These assumptions break down for BOOM.
However, instead of re-writing or forking the Functional Unit s, BOOM provides an abstract Functional Unit class (see Fig. 21) that “wraps” the lower-level functional units with the parameterized auto-generated support code needed to make them work within BOOM. The request and response ports are abstracted, allowing Functional Unit s to provide a unified, interchangeable interface.
Pipelined Functional Units¶
A pipelined Functional Unit can accept a new UOP<Micro-Op (UOP) every cycle. Each UOP<Micro-Op (UOP) will take a known, fixed latency.
Speculation support is provided by auto-generating a pipeline that passes down the UOP<Micro-Op (UOP) meta-data and branch mask in parallel with the UOP<Micro-Op (UOP) within the expert-written Functional Unit . If a UOP<Micro-Op (UOP) is misspeculated, it’s response is de-asserted as it exits the functional unit.
An example pipelined Functional Unit is shown in Fig. 21.
Un-pipelined Functional Units¶
Un-pipelined Functional Unit s (e.g., a divider) take an variable (and unknown) number of cycles to complete a single operation. Once occupied, they de-assert their ready signal and no additional UOPs<Micro-Op (UOP) may be scheduled to them.
Speculation support is provided by tracking the branch mask of the UOP<Micro-Op (UOP) in the Functional Unit.
The only requirement of the expert-written un-pipelined Functional Unit is to provide a kill signal to quickly remove misspeculated UOPs<Micro-Op (UOP). [1]
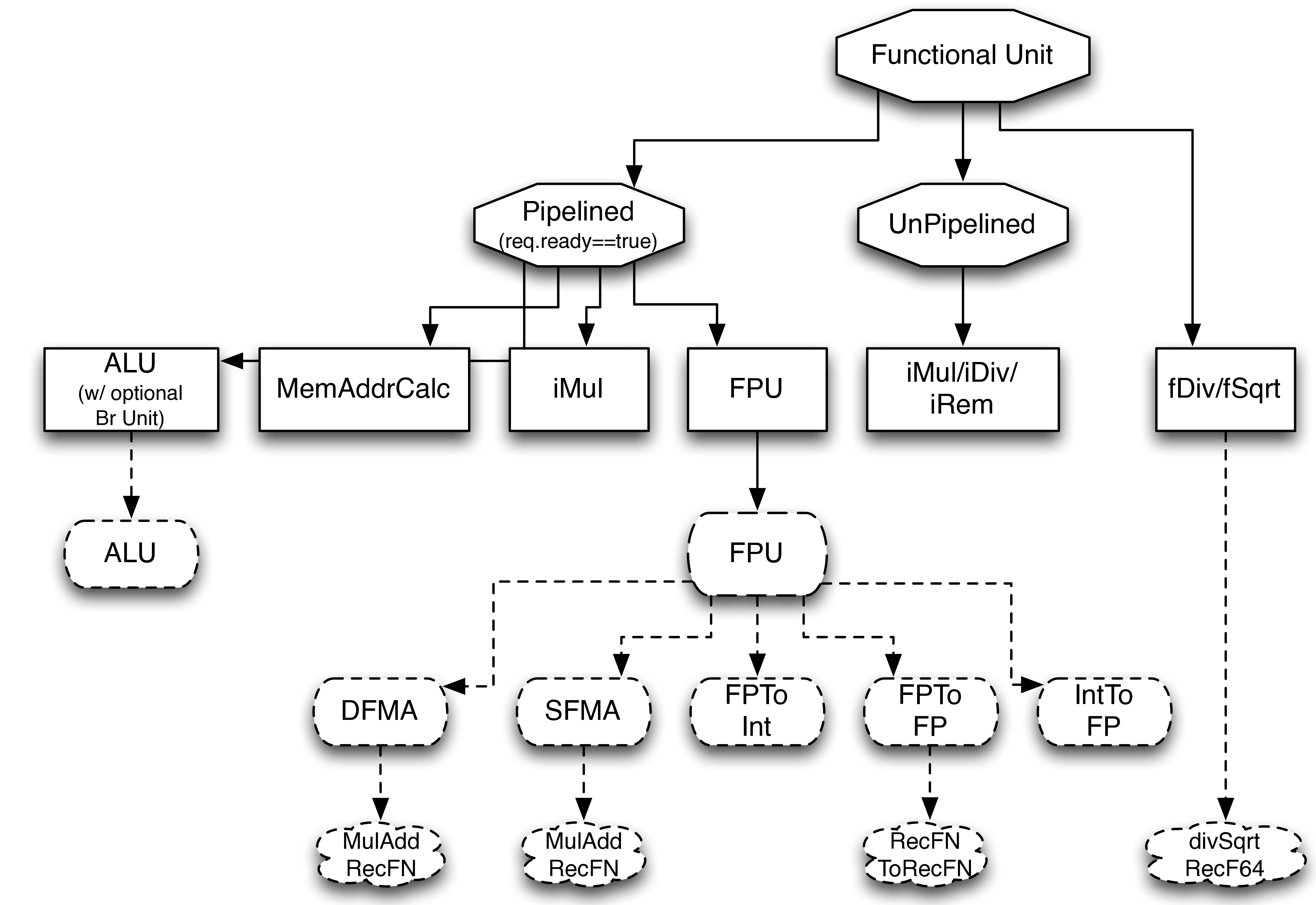
Fig. 22 The dashed ovals are the low-level Functional Unit s written by experts, the squares are
concrete classes that instantiate the low-level Functional Unit s, and the octagons are abstract classes that
provide generic speculation support and interfacing with the BOOM pipeline. The floating point divide
and squart-root unit doesn’t cleanly fit either the Pipelined nor Unpipelined abstract class, and so directly
inherits from the FunctionalUnit super class.
Branch Unit & Branch Speculation¶
The Branch Unit handles the resolution of all branch and jump instructions.
All UOPs<Micro-Op (UOP) that are “inflight” in the pipeline (have an allocated ROB entry) are given a branch mask, where each bit in the branch mask corresponds to an un-executed, inflight branch that the UOP<Micro-Op (UOP) is speculated under. Each branch in Decode is allocated a branch tag, and all following UOPs<Micro-Op (UOP) will have the corresponding bit in the branch mask set (until the branch is resolved by the Branch Unit).
If the branches (or jumps) have been correctly speculated by the Front-end, then the Branch Unit s only action is to broadcast the corresponding branch tag to all inflight UOPs<Micro-Op (UOP) that the branch has been resolved correctly. Each UOP<Micro-Op (UOP) can then clear the corresponding bit in its branch mask, and that branch tag can then be allocated to a new branch in the Decode stage.
If a branch (or jump) is misspeculated, the Branch Unit must redirect the PC to the correct target, kill the Front-end and Fetch Buffer, and broadcast the misspeculated branch tag so that all dependent, inflight UOPs<Micro-Op (UOP) may be killed. The PC redirect signal goes out immediately, to decrease the misprediction penalty. However, the kill signal is delayed a cycle for critical path reasons.
The Front-end must pass down the pipeline the appropriate branch speculation meta-data, so that the correct direction can be reconciled with the prediction. Jump Register instructions are evaluated by comparing the correct target with the PC of the next instruction in the ROB (if not available, then a misprediction is assumed). Jumps are evaluated and handled in the Front-end (as their direction and target are both known once the instruction can be decoded).
BOOM (currently) only supports having one Branch Unit .
Load/Store Unit¶
The Load/Store Unit (LSU) handles the execution of load, store, atomic, and fence operations.
BOOM (currently) only supports having one LSU (and thus can only send one load or store per cycle to memory). [2]
See The Load/Store Unit (LSU) for more details on the LSU.
Floating Point Units¶
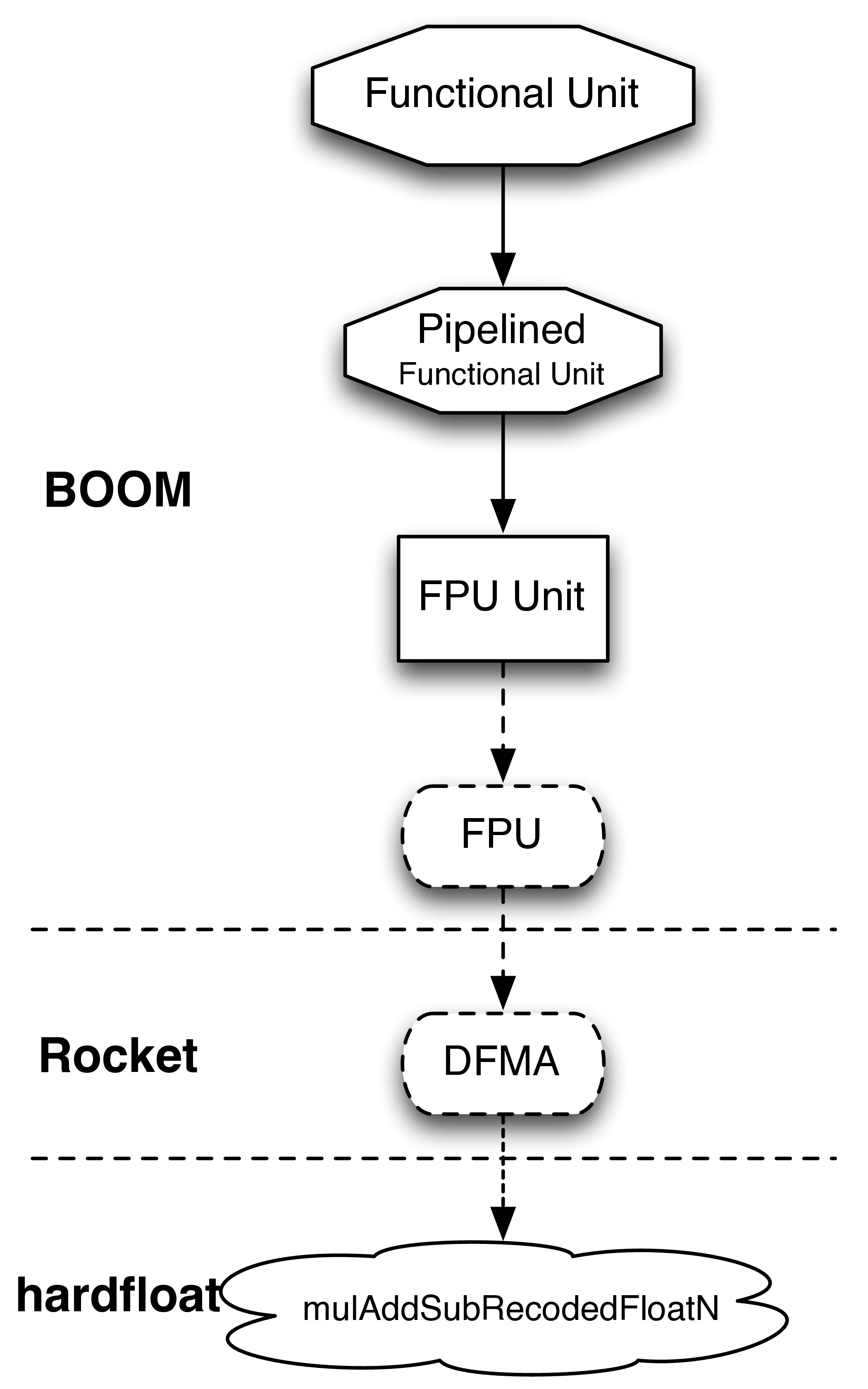
Fig. 23 The class hierarchy of the FPU is shown. The expert-written code is contained within the hardfloat and rocket repositories. The “FPU” class instantiates the Rocket components, which itself is further wrapped by the abstract Functional Unit classes (which provides the out-of-order speculation support).
The low-level floating point units used by BOOM come from the Rocket processor (https://github.com/chipsalliance/rocket-chip) and hardfloat (https://github.com/ucb-bar/berkeley-hardfloat) repositories. Figure Fig. 23 shows the class hierarchy of the FPU.
To make the scheduling of the write-port trivial, all of the pipelined FP units are padded to have the same latency. [3]
Floating Point Divide and Square-root Unit¶
BOOM fully supports floating point divide and square-root operations using a single FDiv/Sqrt (or fdiv for short). BOOM accomplishes this by instantiating a double-precision unit from the hardfloat repository. The unit comes with the following features/constraints:
- expects 65-bit recoded double-precision inputs
- provides a 65-bit recoded double-precision output
- can execute a divide operation and a square-root operation simultaneously
- operations are unpipelined and take an unknown, variable latency
- provides an unstable FIFO interface
Single-precision operations have their operands upscaled to double-precision (and then the output downscaled). [4]
Although the unit is unpipelined, it does not fit cleanly into the
Pipelined/Unpipelined abstraction used by the other Functional Unit s
(see Fig. 22). This is because the unit provides
an unstable FIFO interface: although the unit may provide a ready
signal on Cycle i, there is no guarantee that it will continue
to be ready on Cycle i+1, even if no operations are enqueued.
This proves to be a challenge, as the Issue Queue may attempt to issue
an instruction but cannot be certain the unit will accept it once it
reaches the unit on a later cycle.
The solution is to add extra buffering within the unit to hold instructions until they can be released directly into the unit. If the buffering of the unit fills up, back pressure can be safely applied to the Issue Queue. [5]
Parameterization¶
BOOM provides flexibility in specifying the issue width and the mix of
Functional Unit s in the execution pipeline. See src/main/scala/exu/execution-units.scala
for a detailed view on how to instantiate the execution pipeline in BOOM.
Additional parameterization, regarding things like the latency of the FP
units can be found within the configuration settings (src/main/common/config-mixins.scala).
Control/Status Register Instructions¶
A set of Control/Status Register (CSR) instructions allow the atomic read and write of the Control/Status Registers. These architectural registers are separate from the integer and floating registers, and include the cycle count, retired instruction count, status, exception PC, and exception vector registers (and many more!). Each CSR has its own required privilege levels to read and write to it and some have their own side-effects upon reading (or writing).
BOOM (currently) does not rename any of the CSRs, and in addition to the potential side-effects caused by reading or writing a CSR, BOOM will only execute a CSR instruction non-speculatively. [6] This is accomplished by marking the CSR instruction as a “unique” (or “serializing”) instruction - the ROB must be empty before it may proceed to the Issue Queue (and no instruction may follow it until it has finished execution and been committed by the ROB). It is then issued by the Issue Queue, reads the appropriate operands from the Physical Register File, and is then sent to the CSRFile. [7] The CSR instruction executes in the CSRFile and then writes back data as required to the Physical Register File. The CSRFile may also emit a PC redirect and/or an exception as part of executing a CSR instruction (e.g., a syscall).
The Rocket Custom Co-Processor Interface (RoCC)¶
The RoCC interface accepts a RoCC command and up to two register inputs
from the Control Processor’s scalar register file. The RoCC command is
actually the entire RISC-V instruction fetched by the Control Processor
(a “RoCC instruction”). Thus, each RoCC queue entry is at least
2\*XPRLEN + 32 bits in size (additional RoCC instructions may use the
longer instruction formats to encode additional behaviors).
As BOOM does not store the instruction bits in the ROB, a separate data structure (A “RoCC Shim”) holds the instructions until the RoCC instruction can be committed and the RoCC command sent to the co-processor.
The source operands will also require access to BOOM’s register file. RoCC instructions are dispatched to the Issue Window, and scheduled so that they may access the read ports of the register file once the operands are available. The operands are then written into the RoCC Shim, which stores the operands and the instruction bits until they can be sent to the co-processor. This requires significant state.
After issue to RoCC, we track a queue of in-flight RoCC instructions, since we need to translate the logical destination register identifier from the RoCC response into the previously renamed physical destination register identifier.
Currently the RoCC interface does not support interrupts, exceptions, reusing the BOOM FPU, or direct access to the L1 data cache. This should all be straightforward to add, and will be completed as demand arises.
| [1] | This constraint could be relaxed by waiting for the un-pipelined unit to finish before de-asserting its busy signal and suppressing the valid output signal. |
| [2] | Relaxing this constraint could be achieved by allowing multiple LSUs to talk to their own bank(s) of the data-cache, but the added complexity comes in allocating entries in the LSU before knowing the address, and thus which bank, a particular memory operation pertains to. |
| [3] | Rocket instead handles write-port scheduling by killing and refetching the offending instruction (and all instructions behind it) if there is a write-port hazard detected. This would be far more heavy-handed to do in BOOM. |
| [4] | It is cheaper to perform the SP-DP conversions than it is to instantiate a single-precision fdivSqrt unit. |
| [5] | It is this ability to hold multiple inflight instructions within the unit simultaneously that breaks the “only one instruction at a time” assumption required by the UnpipelinedFunctionalUnit abstract class. |
| [6] | There is a lot of room to play with regarding the CSRs. For example, it is probably a good idea to rename the register (dedicated for use by the supervisor) as it may see a lot of use in some kernel code and it causes no side-effects. |
| [7] | The CSRFile is a Rocket component. |