The BOOM Pipeline¶

Fig. 2 Simplified BOOM Pipeline with Stages
Overview¶
Conceptually, BOOM is broken up into 10 stages: Fetch, Decode, Register Rename, Dispatch, Issue, Register Read, Execute, Memory, Writeback and Commit. However, many of those stages are combined in the current implementation, yielding seven stages: Fetch, Decode/Rename, Rename/Dispatch, Issue/RegisterRead, Execute, Memory and Writeback (Commit occurs asynchronously, so it is not counted as part of the “pipeline”). Fig. 2 shows a simplified BOOM pipeline that has all of the pipeline stages listed.
Stages¶
Fetch¶
Instructions are fetched from instruction memory and pushed into a FIFO queue, known as the Fetch Buffer . Branch prediction also occurs in this stage, redirecting the fetched instructions as necessary. [1]
Decode¶
Decode pulls instructions out of the Fetch Buffer and generates the appropriate Micro-Op(s) (UOPs) to place into the pipeline. [2]
Rename¶
The ISA, or “logical”, register specifiers (e.g. x0-x31) are then renamed into “physical” register specifiers.
Issue¶
UOPs sitting in a Issue Queue wait until all of their operands are ready and are then issued. [3] This is the beginning of the out–of–order piece of the pipeline.
Register Read¶
Issued UOPs s first read their register operands from the unified Physical Register File (or from the Bypass Network)…
Execute¶
… and then enter the Execute stage where the functional units reside. Issued memory operations perform their address calculations in the Execute stage, and then store the calculated addresses in the Load/Store Unit which resides in the Memory stage.
Memory¶
The Load/Store Unit consists of three queues: a Load Address Queue (LAQ), a Store Address Queue (SAQ), and a Store Data Queue (SDQ). Loads are fired to memory when their address is present in the LAQ. Stores are fired to memory at Commit time (and naturally, stores cannot be committed until both their address and data have been placed in the SAQ and SDQ).
Writeback¶
ALU operations and load operations are written back to the Physical Register File.
Commit¶
The Reorder Buffer (ROB), tracks the status of each instruction in the pipeline. When the head of the ROB is not-busy, the ROB commits the instruction. For stores, the ROB signals to the store at the head of the Store Queue (SAQ/SDQ) that it can now write its data to memory.
Branch Support¶
BOOM supports full branch speculation and branch prediction. Each instruction, no matter where it is in the pipeline, is accompanied by a Branch Tag that marks which branches the instruction is “speculated under”. A mispredicted branch requires killing all instructions that depended on that branch. When a branch instructions passes through Rename, copies of the Register Rename Table and the Free List are made. On a mispredict, the saved processor state is restored.
Detailed BOOM Pipeline¶
Although Fig. 2 shows a simplified BOOM pipeline, BOOM supports RV64GC and the privileged ISA which includes single-precision and double-precision floating point, atomics support, and page-based virtual memory. A more detailed diagram is shown below in Fig. 3.
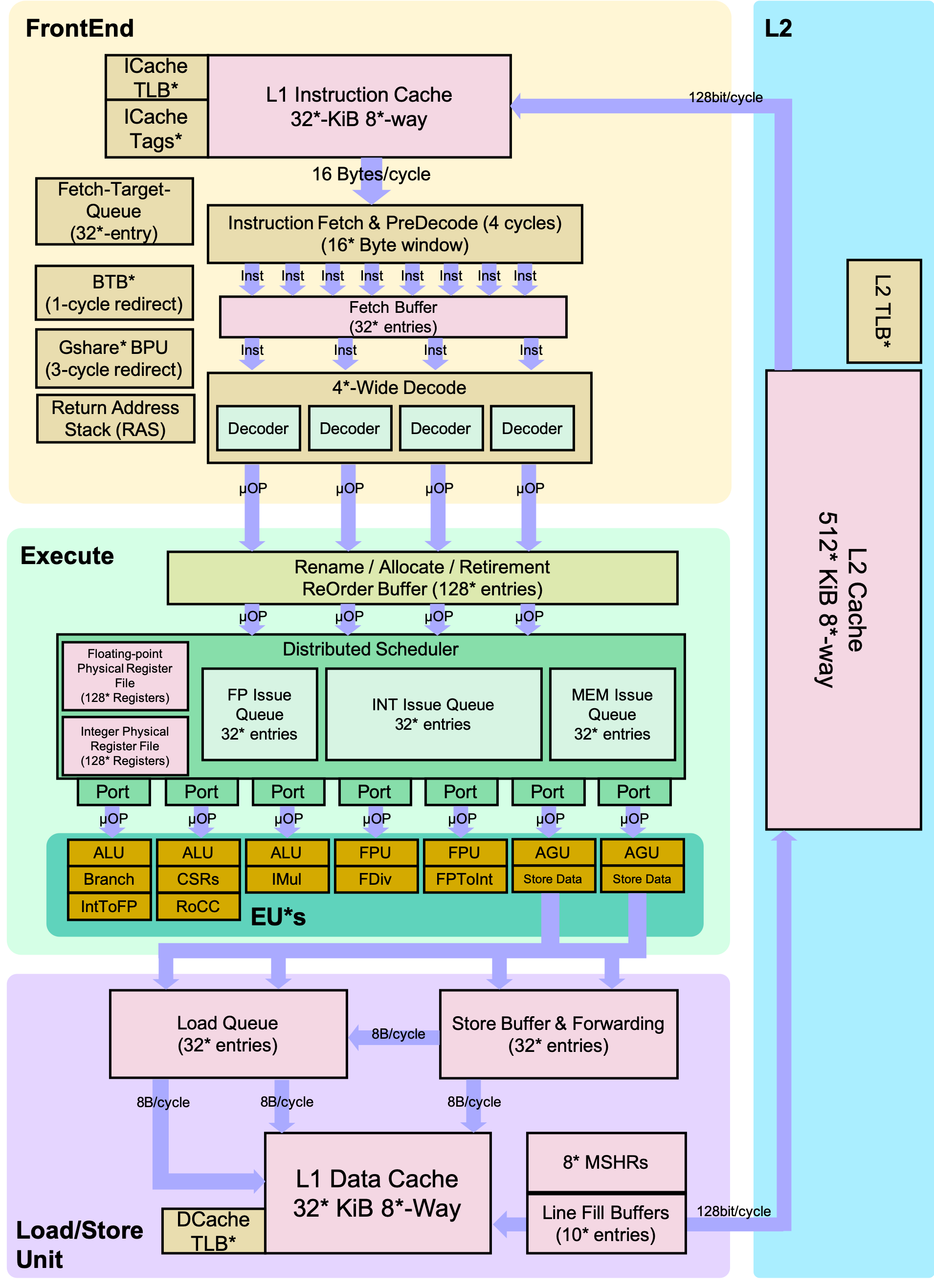
Fig. 3 Detailed BOOM Pipeline. *’s denote where the core can be configured.
| [1] | While the Fetch Buffer is N-entries deep, it can instantly read
out the first instruction on the front of the FIFO. Put another way,
instructions don’t need to spend N cycles moving their way through
the Fetch Buffer if there are no instructions in front of
them. |
| [2] | Because RISC-V is a RISC ISA, currently all instructions generate only a single Micro-Op (UOP) . More details on how store UOPs are handled can be found in The Memory System and the Data-cache Shim. |
| [3] | More precisely, Micro-Ops (UOPs) that are ready assert their request, and the issue scheduler within the Issue Queue chooses which UOPs to issue that cycle. |