The Load/Store Unit (LSU)¶
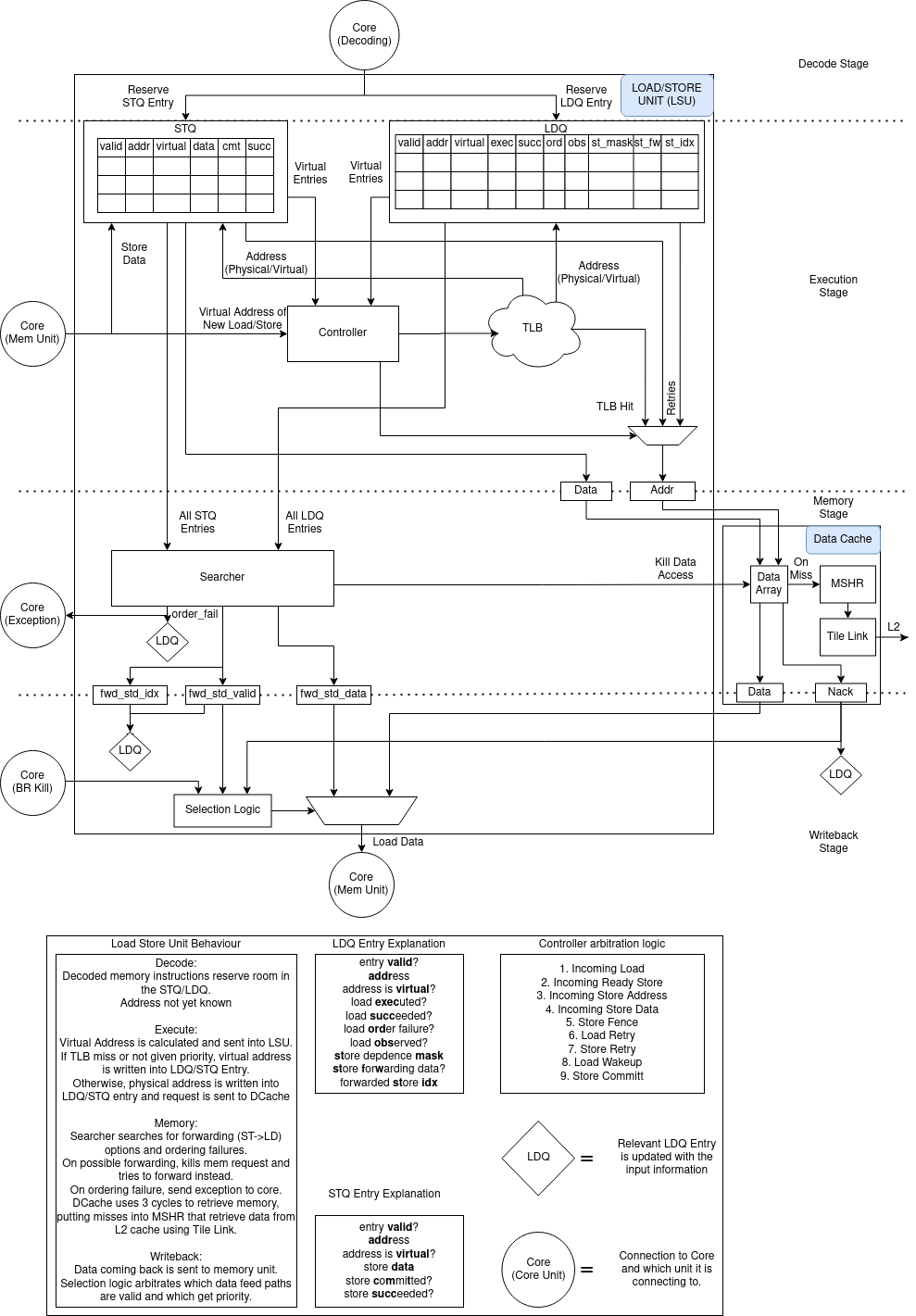
Fig. 24 The Load/Store Unit
The Load/Store Unit (LSU) is responsible for deciding when to fire memory operations to the memory system. There are two queues: the Load Queue (LDQ), and the Store Queue (STQ). Load instructions generate a “uopLD” Micro-Op (UOP). When issued, “uopLD” calculates the load address and places its result in the LDQ. Store instructions (may) generate two UOP s, “uopSTA” (Store Address Generation) and “uopSTD” (Store Data Generation). The STA UOP calculates the store address and updates the address in the STQ entry. The STD UOP moves the store data into the STQ entry. Each of these UOP s will issue out of the Issue Window as soon their operands are ready. See Store Micro-Ops for more details on the store UOP specifics.
Store Instructions¶
Entries in the Store Queue are allocated in the Decode stage ( stq(i).valid is set). A “valid” bit denotes when an entry in the STQ holds a valid address and valid data (stq(i).bits.addr.valid and stq(i).bits.data.valid). Once a store instruction is committed, the corresponding entry in the Store Queue is marked as committed. The store is then free to be fired to the memory system at its convenience. Stores are fired to the memory in program order.
Store Micro-Ops¶
Stores are inserted into the issue window as a single instruction (as opposed to being broken up into separate addr-gen and data-gen UOP s). This prevents wasteful usage of the expensive issue window entries and extra contention on the issue ports to the LSU. A store in which both operands are ready can be issued to the LSU as a single UOP which provides both the address and the data to the LSU. While this requires store instructions to have access to two register file read ports, this is motivated by a desire to not cut performance in half on store-heavy code. Sequences involving stores to the stack should operate at IPC=1!
However, it is common for store addresses to be known well in advance of the store data. Store addresses should be moved to the STQ as soon as possible to allow later loads to avoid any memory ordering failures. Thus, the issue window will emit uopSTA or uopSTD UOP s as required, but retain the remaining half of the store until the second operand is ready.
Load Instructions¶
Entries in the Load Queue (LDQ) are allocated in the Decode stage
(ldq(i).valid). In Decode, each load entry is also given a store
mask (ldq(i).bits.st\_dep\_mask), which marks which stores in the Store
Queue the given load depends on. When a store is fired to memory and
leaves the Store Queue, the appropriate bit in the store mask is cleared.
Once a load address has been computed and placed in the LDQ, the
corresponding valid bit is set (ldq(i).addr.valid).
Loads are optimistically fired to memory on arrival to the LSU (getting loads fired early is a huge benefit of out–of–order pipelines). Simultaneously, the load instruction compares its address with all of the store addresses that it depends on. If there is a match, the memory request is killed. If the corresponding store data is present, then the store data is forwarded to the load and the load marks itself as having succeeded. If the store data is not present, then the load goes to sleep. Loads that have been put to sleep are retried at a later time. [1]
The BOOM Memory Model¶
BOOM follows the RVWMO memory consistency model.
BOOM currently exhibits the following behavior:
- Write -> Read constraint is relaxed (newer loads may execute before older stores).
- Read -> Read constraint is maintained (loads to the same address appear in order).
- A thread can read its own writes early.
Ordering Loads to the Same Address¶
The RISC-V WMO memory model requires that loads to the same address be ordered. [2] This requires loads to search against other loads for potential address conflicts. If a younger load executes before an older load with a matching address, the younger load must be replayed and the instructions after it in the pipeline flushed. However, this scenario is only required if a cache coherence probe event snooped the core’s memory, exposing the reordering to the other threads. If no probe events occurred, the load re-ordering may safely occur.
Memory Ordering Failures¶
The Load/Store Unit has to be careful regarding store -> load dependences. For the best performance, loads need to be fired to memory as soon as possible.
sw x1 -> 0(x2)
ld x3 <- 0(x4)
However, if x2 and x4 reference the same memory address, then the load in our example depends on the earlier store. If the load issues to memory before the store has been issued, the load will read the wrong value from memory, and a memory ordering failure has occurred. On an ordering failure, the pipeline must be flushed and the Rename Map Tables reset. This is an incredibly expensive operation.
To discover ordering failures, when a store commits, it checks the entire LDQ for any address matches. If there is a match, the store checks to see if the load has executed, and if it got its data from memory or if the data was forwarded from an older store. In either case, a memory ordering failure has occurred.
See Fig. 24 for more information about the Load/Store Unit.
| [1] | Higher-performance processors will track why a load was put to sleep and wake it up once the blocking cause has been alleviated. |
| [2] | Technically, a fence.r.r could be used to provide the correct execution of software on machines that reorder dependent loads. However, there are two reasons for an ISA to disallow re-ordering of dependent loads: 1) no other popular ISA allows this relaxation, and thus porting software to RISC-V could face extra challenges, and 2) cautious software may be too liberal with the appropriate fence instructions causing a slow-down in software. Thankfully, enforcing ordered dependent loads may not actually be very expensive. For one, load addresses are likely to be known early - and are probably likely to execute in-order anyways. Second, misordered loads are only a problem in the cache of a cache coherence probe, so performance penalty is likely to be negligible. The hardware cost is also negligible - loads can use the same CAM search port on the LAQ that stores must already use. While this may become an issue when supporting one load and one store address calculation per cycle, the extra CAM search port can either be mitigated via banking or will be small compared to the other hardware costs required to support more cache bandwidth. |