The Next-Line Predictor (NLP)¶
BOOM core’s Front-end fetches instructions and predicts every cycle where to fetch the next instructions. If a misprediction is detected in BOOM’s Back-end, or BOOM’s own Backing Predictor (BPD) wants to redirect the pipeline in a different direction, a request is sent to the Front-end and it begins fetching along a new instruction path.
The Next-Line Predictor (NLP) takes in the current PC being used to fetch instructions (the Fetch PC) and predicts combinationally where the next instructions should be fetched for the next cycle. If predicted correctly, there are no pipeline bubbles.
The NLP is an amalgamation of a fully-associative Branch Target Buffer (BTB), Bi-Modal Table (BIM) and a Return Address Stack (RAS) which work together to make a fast, but reasonably accurate prediction.
NLP Predictions¶
The Fetch PC first performs a tag match to find a uniquely matching BTB entry. If a hit occurs, the BTB entry will make a prediction in concert with the RAS as to whether there is a branch, jump, or return found in the Fetch Packet and which instruction in the Fetch Packet is to blame. The BIM is used to determine if that prediction made was a branch taken or not taken. The BTB entry also contains a predicted PC target, which is used as the Fetch PC on the next cycle.
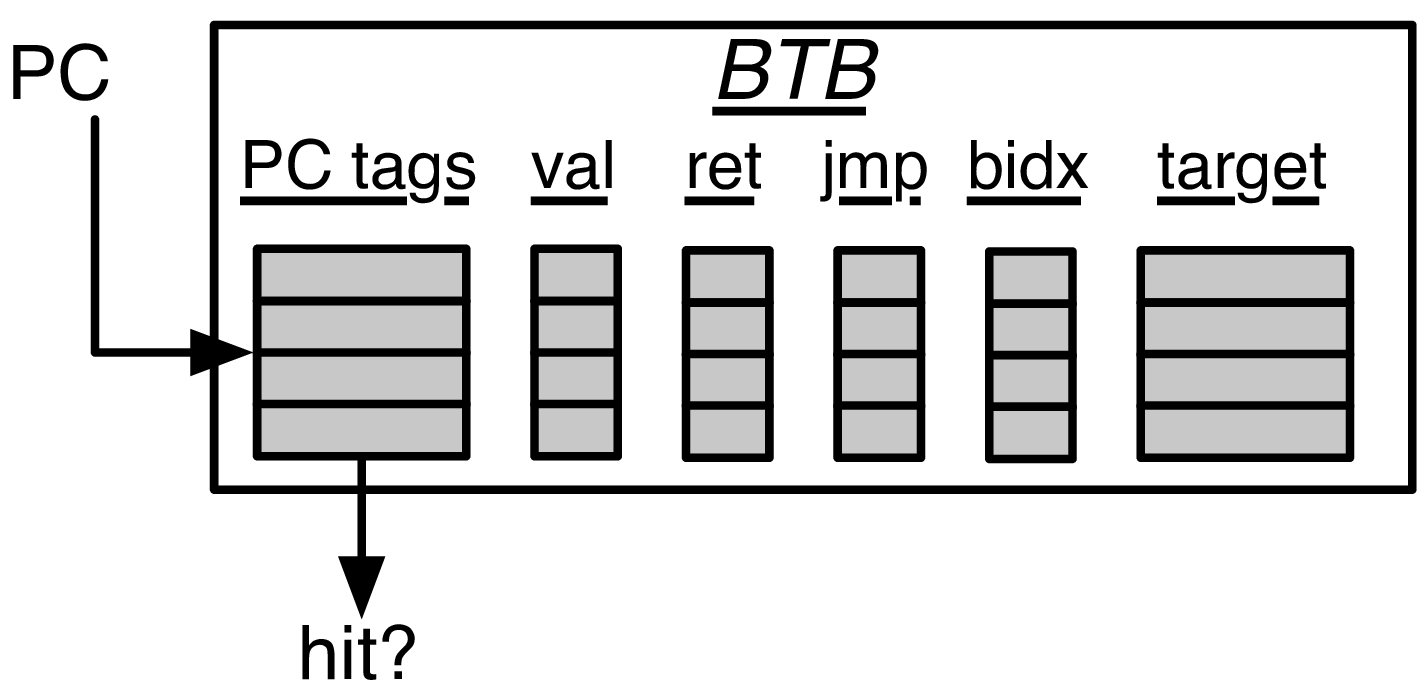
Fig. 7 The Next-Line Predictor (NLP) Unit. The Fetch PC scans the BTB’s “PC tags” for a match. If a match is found (and the entry is valid), the Bi-Modal Table (BIM) and RAS are consulted for the final verdict. If the entry is a “ret” (return instruction), then the target comes from the RAS. If the entry is a unconditional “jmp” (jump instruction), then the BIM is not consulted. The “bidx”, or branch index, marks which instruction in a superscalar Fetch Packet is the cause of the control flow prediction. This is necessary to mask off the other instructions in the Fetch Packet that come over the taken branch
The hysteresis bits in the BIM are only used on a BTB entry hit and if the predicting instruction is a branch.
If the BTB entry contains a return instruction, the RAS stack is used to provide the predicted return PC as the next Fetch PC. The actual RAS management (of when to or the stack) is governed externally.
For area-efficiency, the high-order bits of the PC tags and PC targets are stored in a compressed file.
NLP Updates¶
Each branch passed down the pipeline remembers not only its own PC, but also its Fetch PC (the PC of the head instruction of its Fetch Packet ). [2]
BTB Updates¶
The BTB is updated only when the Front-end is redirected to take a branch or jump by either the Branch Unit (in the Execute stage) or the BPD (later in the Fetch stages). [3]
If there is no BTB entry corresponding to the taken branch or jump, an new entry is allocated for it.
RAS Updates¶
The RAS is updated during the Fetch stages once the instructions in the Fetch Packet have been decoded. If the taken instruction is a call [4] , the return address is pushed onto the RAS. If the taken instruction is a return, then the RAS is popped.
Superscalar Predictions¶
When the NLP makes a prediction, it is actually using the BTB to tag match against the predicted branch’s Fetch PC, and not the PC of the branch itself. The NLP must predict across the entire Fetch Packet which of the many possible branches will be the dominating branch that redirects the PC. For this reason, we use a given branch’s Fetch PC rather than its own PC in the BTB tag match. [5]
| [2] | In reality, only the very lowest bits must be saved, as the higher-order bits will be the same. |
| [3] | The BTB relies on a little cleverness - when redirecting the PC on a misprediction, this new Fetch PC is the same as the update PC that needs to be written into a new BTB entry’s target PC field. This “coincidence” allows the PC compression table to use a single search port - it is simultaneously reading the table for the next prediction while also seeing if the new Update PC already has the proper high-order bits allocated for it. |
| [4] | While RISC-V does not have a dedicated call instruction, it can be inferred by checking for a JAL or JALR instruction with a writeback destination to x1 (aka, the return address register). |
| [5] | Each BTB entry corresponds to a single Fetch PC, but it is helping to predict across an entire Fetch Packet. However, the BTB entry can only store meta-data and target-data on a single control-flow instruction. While there are certainly pathological cases that can harm performance with this design, the assumption is that there is a correlation between which branch in a Fetch Packet is the dominating branch relative to the Fetch PC, and - at least for narrow fetch designs - evaluations of this design has shown it is very complexity-friendly with no noticeable loss in performance. Some other designs instead choose to provide a whole bank of BTBs for each possible instruction in the Fetch Packet . |